บริการ ติดตั้ง Local Model LLM
ออกแบบ ติดตั้ง Local Model หรือ Large Language Model สำหรับองค์กร
Production-Ready, Secure, Scalable, and Cost-Controllable
LLMOps คือการทำให้การใช้งาน Local Model LLM ในองค์กรไม่หยุดอยู่แค่การทดลอง แต่สามารถนำไปใช้งานจริงได้อย่างเป็นระบบ ตั้งแต่โครงสร้างพื้นฐาน การให้บริการโมเดล การเชื่อมต่อข้อมูลภายใน การทำ RAG ไปจนถึงการดูแล Monitoring, Security และ Governance
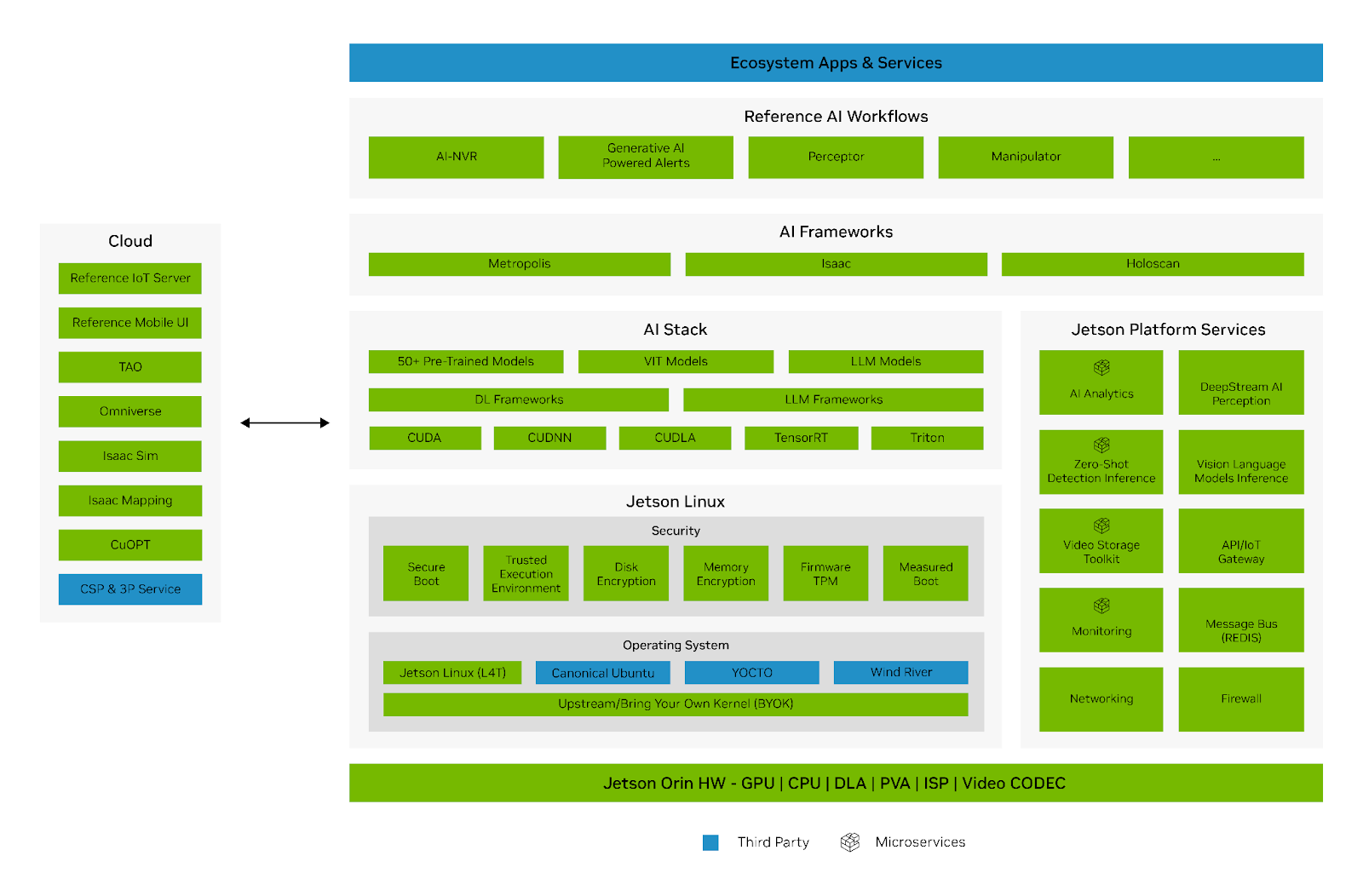
Ref. https://developer.nvidia.com/embedded/develop/software
Our Expertise
- ประสบการณ์กับ Large-Scale Models We have hands-on experience designing and running large-scale models such as DeepSeek 671B, Llama 3.1 405B, and OSS GPT 120B for real enterprise-grade workloads.
- Expertise in Model Serving Stack We have deployed and operated Model Serving systems using KServe, vLLM, Ray Serve, and Kubeflow to enable flexible and scalable inference.
- RAG on Enterprise GPU Infrastructure We have experience deploying RAG systems on high-end GPU Infrastructure such as NVIDIA H100, H200, B200, and MI300 to support high-performance AI workloads.
- AI Storage & Data Architecture We design and manage High Performance Storage tailored for AI Workloads including Inference, RAG, and Training, and help architect efficient S3-based data structures.
- Training & AI Platform Deployment We can advise, design, and deploy Model Training systems on GPU Servers, including helping plan Data Pipeline management and Environment setup for production-ready use.
Our Services
- บริการ LLM Infrastructure Design
We architect infrastructure for LLM deployments across On-Premise, Cloud, and Hybrid environments, tailored to your workload scale, budget, and organizational goals. - บริการ Local Model Deployment & Serving
ติดตั้งและปรับแต่งระบบสำหรับ Deploy โมเดลและเปิดให้บริการผ่าน API เพื่อให้แอปพลิเคชันหรือทีมภายในสามารถเรียกใช้งานได้อย่างมีประสิทธิภาพโดย vLLM บน Kubernetes - บริการ RAG & Data Integration
We connect LLMs to documents, knowledge bases, or internal organizational data, enabling the model to answer questions accurately with references to real business data. - บริการ Monitoring & Optimization
We set up monitoring systems for model and infrastructure performance metrics such as Latency, GPU Utilization, Error Rate, and cost, enabling easier management and optimization. - บริการ Security & Governance
We design security measures including access control, log management, and data usage guidelines to support enterprise-grade deployments. - บริการ Managed LLMOps Services
We provide end-to-end LLM system management covering infrastructure maintenance, system monitoring, updates, troubleshooting, and continuous improvement.
Technologies & Environments We Support
- Large Language Models Supporting both Open-Source and Enterprise Models for Inference, Fine-Tuning, and Enterprise AI Use Cases.
- Serving Platforms Supporting KServe, vLLM, Ray Serve, Kubeflow, and Kubernetes-based AI Platforms.
- GPU Infrastructure Supporting design and operation on GPU Servers and GPU Clusters such as NVIDIA H100, H200, B200, and AMD MI300.
- Storage & Data Layer Supporting data infrastructure setup on S3, High Performance Storage, and Data Architecture suited for AI Pipelines.
Ideal For
- Organizations Wanting to Use LLM Internally
Suitable for teams looking to build AI Assistants, Chatbots, or internal document search systems. - Businesses Moving from PoC to Production
We help transition from experimental systems to stable, real-world deployments that support users long-term. - Organizations That Need Full Control Over Data and Systems
Suited for high-privacy workloads requiring deployment on Private Environments, On-Premise, or Hybrid Architecture. - Teams Needing Training and Serving on the Same Platform
Ideal for organizations needing end-to-end AI data management including Inference, RAG, and Fine-Tuning on a unified platform.
What You Will Get
- Production-Ready AI Platform A production-ready system architecture supporting Model Serving, RAG, Training, and internal organizational data integration.
- Better Performance & Cost Control You get a system designed specifically for AI Workloads, improving performance and better controlling infrastructure costs.
- Secure & Scalable Foundation You get a system that is secure, standards-compliant, and scalable to grow with your business.
Why Choose Us
- Real Experience with Models and Infrastructure We go beyond theoretical understanding — we have direct, hands-on experience running and serving large-scale models on real GPU Infrastructure.
- Understanding Models, Platforms, and Storage เราดูทั้งระบบตั้งแต่ Model Serving, RAG, Training, Storage, Kubernetes และ Data Architecture ให้ทำงานร่วมกันได้อย่างเหมาะสม
- Built for Real Enterprise Workloads Every design is focused on real Production use — not just a Demo or Prototype.
Get Started with Us
If you are looking for a team to help set up an LLM system that is truly production-ready for your organization
เราพร้อมช่วยคุณออกแบบ ติดตั้ง และดูแลระบบอย่างครบวงจร ตั้งแต่ Model Serving, RAG, Training ไปจนถึง AI Data Platform
Turn LLM from a concept into a working real-world system.
Interested? Contact us by Email [email protected]
AI Chat Bots
Used to answer questions from internal documents, manuals, or company knowledge bases — helping reduce team workload and speed up information access.
Model Serving
รองรับการนำ LLM ไปเชื่อมต่อกับระบบหรือแอปพลิเคชันของธุรกิจ เช่น AI Agent, AI Assistant, Customer Support หรือระบบวิเคราะห์ข้อมูล
RAG
Helps users search and summarize information from files, documents, or internal organizational data — accurately and quickly.
PRIVATE LLM
Ideal for organizations that need to run models within their own systems — for better control over data, security, and access.