บริการ ติดตั้ง Local Model LLM
ออกแบบ ติดตั้ง Local Model หรือ Large Language Model สำหรับองค์กร
พร้อมใช้งานจริงในระดับ Production ปลอดภัย ขยายต่อได้ และควบคุมต้นทุนได้
LLMOps คือการทำให้การใช้งาน Local Model LLM ในองค์กรไม่หยุดอยู่แค่การทดลอง แต่สามารถนำไปใช้งานจริงได้อย่างเป็นระบบ ตั้งแต่โครงสร้างพื้นฐาน การให้บริการโมเดล การเชื่อมต่อข้อมูลภายใน การทำ RAG ไปจนถึงการดูแล Monitoring, Security และ Governance
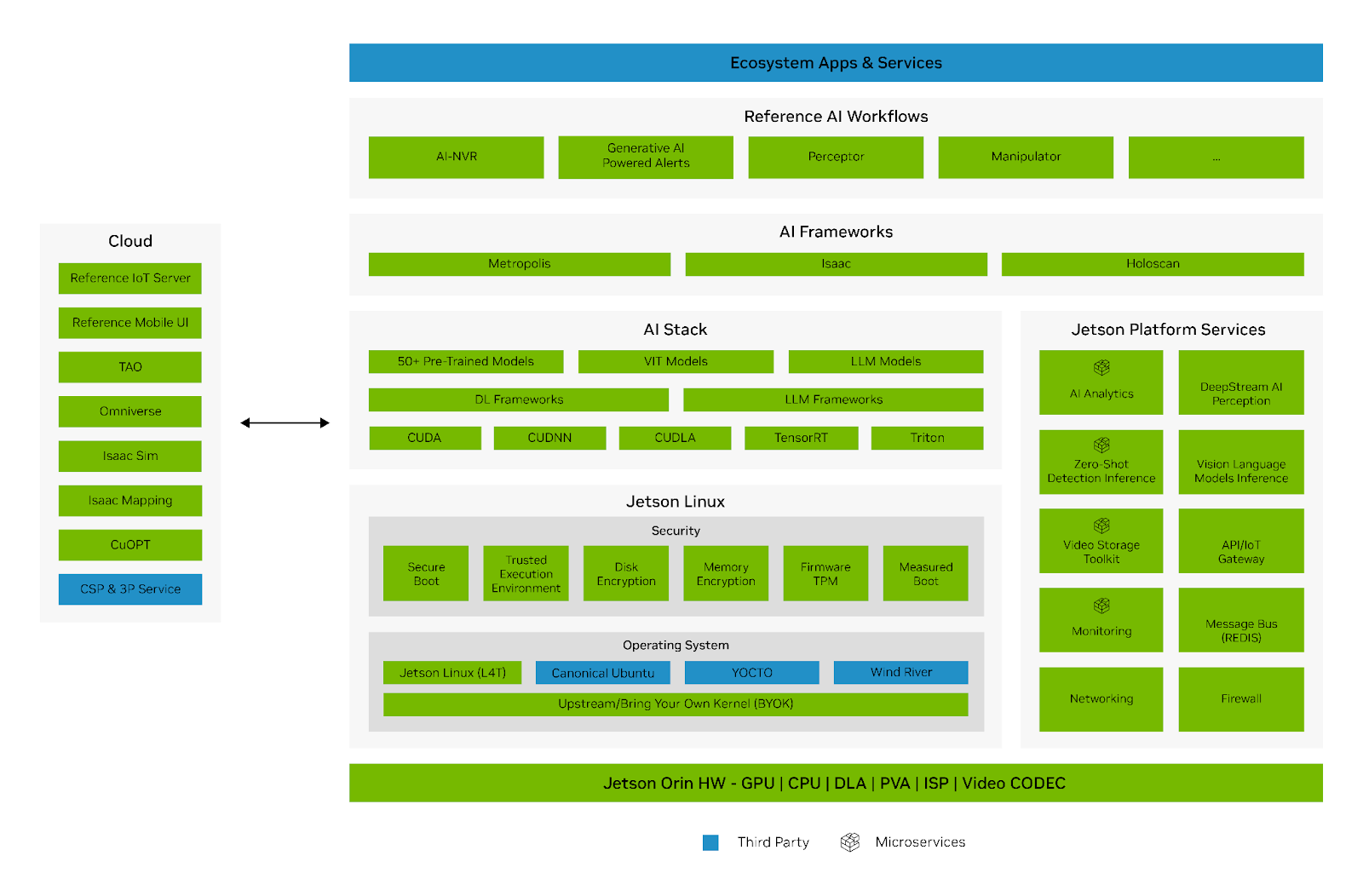
Ref. https://developer.nvidia.com/embedded/develop/software
ความเชี่ยวชาญของเรา
- ประสบการณ์กับ Large-Scale Models เรามีประสบการณ์ในการออกแบบและรันโมเดลขนาดใหญ่ เช่น DeepSeek 671B, Llama 3.1 405B และ OSS GPT 120B สำหรับงานจริงในระดับองค์กร
- Expertise in Model Serving Stack เราเคยใช้งานและติดตั้งระบบสำหรับ Model Serving ด้วย KServe, vLLM, Ray Serve และ Kubeflow เพื่อให้รองรับการใช้งานได้อย่างยืดหยุ่นและขยายต่อได้
- RAG on Enterprise GPU Infrastructure เรามีประสบการณ์ในการ Deploy ระบบ RAG บน GPU Infrastructure ระดับสูง เช่น NVIDIA H100, H200, B200 และ MI300 เพื่อรองรับงาน AI ที่ต้องการประสิทธิภาพสูง
- AI Storage & Data Architecture ออกแบบและจัดการ High Performance Storage ให้เหมาะกับ AI Workloads ทั้งสำหรับ Inference, RAG และ Training พร้อมช่วยวางโครงสร้างข้อมูลบน S3 ให้ใช้งานได้อย่างมีประสิทธิภาพ
- Training & AI Platform Deployment สามารถแนะนำ ออกแบบ และติดตั้งระบบสำหรับ Model Training บน GPU Server รวมถึงช่วยวางแนวทางการจัดการ Data Pipeline และ Environment ให้พร้อมใช้งานจริง
บริการของเรา
- บริการ LLM Infrastructure Design
ออกแบบสถาปัตยกรรมสำหรับรองรับการใช้งาน LLM ทั้งแบบ On-Premise, Cloud และ Hybrid ให้เหมาะกับขนาดงาน งบประมาณ และเป้าหมายขององค์กร - บริการ Local Model Deployment & Serving
ติดตั้งและปรับแต่งระบบสำหรับ Deploy โมเดลและเปิดให้บริการผ่าน API เพื่อให้แอปพลิเคชันหรือทีมภายในสามารถเรียกใช้งานได้อย่างมีประสิทธิภาพโดย vLLM บน Kubernetes - บริการ RAG & Data Integration
เชื่อมต่อ LLM เข้ากับเอกสาร ฐานความรู้ หรือข้อมูลภายในองค์กร เพื่อให้โมเดลตอบคำถามได้แม่นยำและอ้างอิงข้อมูลจริงของธุรกิจ - บริการ Monitoring & Optimization
วางระบบติดตามประสิทธิภาพของโมเดลและโครงสร้างพื้นฐาน เช่น Latency, GPU Utilization, Error Rate และต้นทุน เพื่อให้บริหารจัดการได้ง่ายขึ้น - บริการ Security & Governance
ออกแบบมาตรการด้านความปลอดภัย การควบคุมสิทธิ์การเข้าถึง การเก็บ Log และแนวทางการใช้งานข้อมูล เพื่อรองรับการใช้งานในระดับองค์กร - บริการ Managed LLMOps Services
ดูแลระบบ LLM แบบครบวงจร ตั้งแต่การดูแลโครงสร้างพื้นฐาน การเฝ้าระวังระบบ การอัปเดต ไปจนถึงการช่วยแก้ปัญหาและปรับปรุงต่อเนื่อง
เทคโนโลยีและสภาพแวดล้อมที่เรารองรับ
- Large Language Models รองรับงานทั้ง Open-Source และ Enterprise Models สำหรับ Inference, Fine-Tuning และ Enterprise AI Use Cases
- Serving Platforms รองรับ KServe, vLLM, Ray Serve, Kubeflow และ Kubernetes-based AI Platforms
- GPU Infrastructure รองรับการออกแบบและใช้งานบน GPU Server และ GPU Cluster เช่น NVIDIA H100, H200, B200 และ AMD MI300
- Storage & Data Layer รองรับการวางระบบข้อมูลบน S3, High Performance Storage และ Data Architecture ที่เหมาะกับ AI Pipeline
เหมาะสำหรับ
- องค์กรที่ต้องการใช้ LLM ภายในบริษัท
เหมาะสำหรับทีมที่ต้องการสร้าง AI Assistant, Chatbot หรือระบบค้นหาข้อมูลจากเอกสารภายใน - ธุรกิจที่เริ่มจาก PoC และต้องการขึ้น Production
ช่วยเปลี่ยนจากระบบทดลองให้กลายเป็นระบบที่เสถียร ใช้งานได้จริง และรองรับผู้ใช้ในระยะยาว - องค์กรที่ต้องการควบคุมข้อมูลและระบบเอง
เหมาะกับงานที่ต้องการความเป็นส่วนตัวสูง และต้องการ Deploy บน Private Environment, On-Premise หรือ Hybrid Architecture - ทีมที่ต้องการ Training และ Serving ในแพลตฟอร์มเดียวกัน
เหมาะสำหรับองค์กรที่ต้องการทั้ง Inference, RAG, Fine-Tuning และการบริหารจัดการข้อมูล AI ในภาพรวม
สิ่งที่ลูกค้าจะได้รับ
- Production-Ready AI Platform โครงสร้างระบบที่พร้อมใช้งานจริง รองรับทั้ง Model Serving, RAG, Training และการเชื่อมต่อข้อมูลภายในองค์กร
- Better Performance & Cost Control ได้ระบบที่ออกแบบให้เหมาะกับ AI Workloads ช่วยเพิ่มประสิทธิภาพและควบคุมต้นทุนโครงสร้างพื้นฐานได้ดีขึ้น
- Secure & Scalable Foundation ได้ระบบที่ปลอดภัย มีมาตรฐาน และสามารถขยายต่อได้ตามการเติบโตของธุรกิจ
ทำไมต้องเลือกเรา
- มีประสบการณ์กับโมเดลและโครงสร้างพื้นฐานจริง เราไม่ได้มีเพียงความเข้าใจเชิงทฤษฎี แต่มีประสบการณ์ตรงในการรันและให้บริการโมเดลขนาดใหญ่บน GPU Infrastructure จริง
- เข้าใจทั้ง Model, Platform และ Storage เราดูทั้งระบบตั้งแต่ Model Serving, RAG, Training, Storage, Kubernetes และ Data Architecture ให้ทำงานร่วมกันได้อย่างเหมาะสม
- เหมาะกับงานจริงขององค์กร ทุกการออกแบบเน้นการใช้งานจริงใน Production ไม่ใช่เพียง Demo หรือ Prototype
เริ่มต้นกับเรา
หากคุณกำลังมองหาทีมที่ช่วยวางระบบ LLM ให้พร้อมใช้งานจริงในองค์กร
เราพร้อมช่วยคุณออกแบบ ติดตั้ง และดูแลระบบอย่างครบวงจร ตั้งแต่ Model Serving, RAG, Training ไปจนถึง AI Data Platform
เปลี่ยน LLM จากแนวคิด ให้กลายเป็นระบบที่ใช้งานได้จริง
สนใจติดต่อ Email [email protected]
AI Chat bots
ใช้ตอบคำถามจากเอกสารภายใน คู่มือ หรือฐานความรู้ของบริษัท เพื่อช่วยลดภาระทีมงานและเพิ่มความเร็วในการเข้าถึงข้อมูล
Model Serving
รองรับการนำ LLM ไปเชื่อมต่อกับระบบหรือแอปพลิเคชันของธุรกิจ เช่น AI Agent, AI Assistant, Customer Support หรือระบบวิเคราะห์ข้อมูล
RAG
ช่วยให้ผู้ใช้งานค้นหาและสรุปข้อมูลจากไฟล์ เอกสาร หรือข้อมูลภายในองค์กรได้อย่างแม่นยำและรวดเร็ว
PRIVATE LLM
เหมาะสำหรับองค์กรที่ต้องการใช้งานโมเดลภายในระบบของตัวเอง เพื่อควบคุมข้อมูล ความปลอดภัย และการเข้าถึงได้ดียิ่งขึ้น