LLMOps คืออะไร
LLMOps ย่อมาจาก Large Language Model Operations เป็นแนวคิดที่ต่อยอดมาจาก DevOps, MLOps และ Platform Engineering เพื่อให้การจัดการระบบ LLM มีความเป็นระบบมากขึ้น ครอบคลุมตั้งแต่การเตรียมโครงสร้างพื้นฐาน การ deploy model serving การเชื่อมต่อข้อมูลผ่าน RAG การติดตามประสิทธิภาพ การควบคุมเวอร์ชัน ไปจนถึงการดูแลความปลอดภัยและต้นทุน
ทำไมองค์กรที่ใช้ AI จริงจังจึงต้องมี LLMOps
LLMOps คือแนวทางในการออกแบบ ติดตั้ง ดูแล และปรับปรุงระบบที่เกี่ยวข้องกับ Large Language Models (LLMs) ให้สามารถใช้งานได้จริงในระดับ Production ไม่ใช่เพียงแค่ทดลองรันโมเดลหรือทำ Demo ชั่วคราว แต่เป็นการทำให้ AI กลายเป็นส่วนหนึ่งของระบบธุรกิจอย่างมีมาตรฐาน ปลอดภัย และขยายต่อได้
ในช่วงที่ผ่านมา หลายองค์กรเริ่มนำ LLM มาใช้กับงานอย่าง AI Chatbot, Knowledge Search, Document Assistant, Internal Copilot และระบบวิเคราะห์ข้อมูลจากเอกสารจำนวนมาก แต่เมื่อเริ่มใช้งานจริง ความท้าทายจะไม่ได้อยู่แค่การเลือกโมเดลที่เก่งที่สุดเท่านั้น แต่รวมถึงการ deploy โมเดลอย่างไรให้เสถียร, เชื่อมต่อข้อมูลภายในอย่างไรให้แม่นยำ, คุมต้นทุนอย่างไร, วางระบบ Monitoring อย่างไร และดูแล Security อย่างไรให้เหมาะกับองค์กร
LLMOps จึงเป็นรากฐานสำคัญที่ช่วยให้องค์กรเปลี่ยนจากการ “ทดลองใช้ LLM” ไปสู่การ “ใช้งาน AI ได้จริง”
ถ้าอธิบายแบบง่ายที่สุด LLMOps คือการทำให้โมเดลภาษาไม่ได้แค่ “รันได้” แต่ “ใช้งานได้จริง” ในสภาพแวดล้อมขององค์กร
ทำไม LLMOps ถึงสำคัญ
หลายทีมเริ่มต้นจากการทดสอบโมเดลบนเครื่องเดียว หรือเชื่อม API เพื่อทำ Proof of Concept ซึ่งมักทำได้ไม่ยาก แต่เมื่อระบบต้องรองรับผู้ใช้จริง ความซับซ้อนจะเพิ่มขึ้นทันที เช่น ปริมาณผู้ใช้งานสูงขึ้น, ข้อมูลภายในองค์กรมีความอ่อนไหว, ต้องการ response time ที่เสถียร, ต้องรองรับหลายโมเดล, หรือเริ่มมีความต้องการด้าน governance และ audit
หากไม่มี LLMOps ที่ดี องค์กรอาจเจอปัญหาเหล่านี้:
- ระบบตอบช้าหรือไม่เสถียรเมื่อมีผู้ใช้งานจำนวนมาก
- ต้นทุน GPU หรือ API สูงเกินความจำเป็น
- ข้อมูลภายในถูกใช้งานโดยไม่มีการควบคุมที่เหมาะสม
- ไม่มี monitoring ที่ดีพอในการวิเคราะห์ปัญหา
- การ deploy model ใหม่หรือเปลี่ยน version ทำได้ยาก
- การเชื่อมต่อข้อมูลภายในไม่มีคุณภาพ ทำให้คำตอบไม่แม่นยำ
LLMOps เข้ามาช่วยจัดการเรื่องเหล่านี้อย่างเป็นระบบ
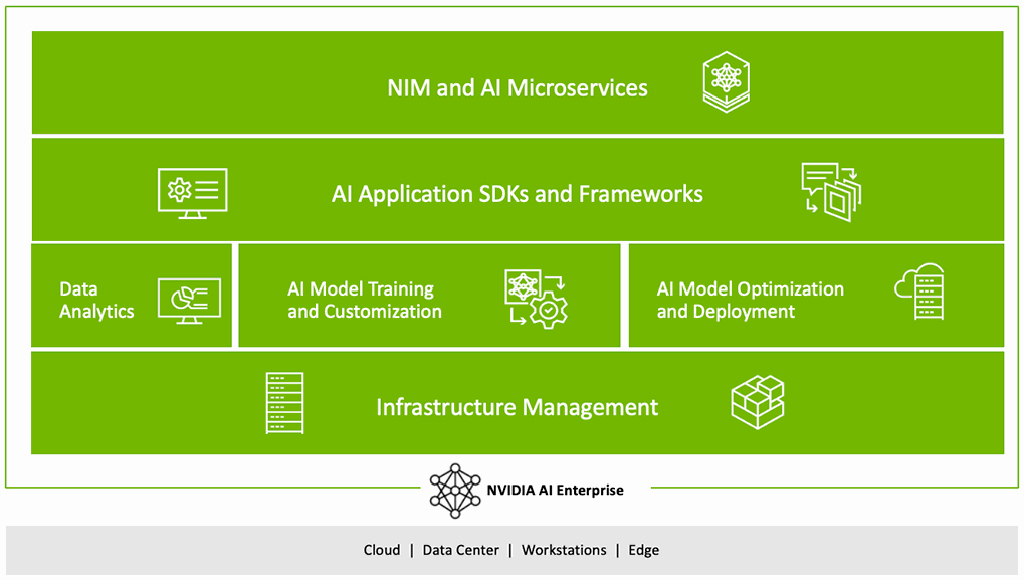
LLMOps ครอบคลุมอะไรบ้าง
1. Infrastructure for Large Language Models (LLM)
การใช้งาน LLM ในระดับ Production ต้องมีโครงสร้างพื้นฐานที่เหมาะสม ไม่ว่าจะเป็น GPU server, Kubernetes platform, networking, storage และระบบที่รองรับการ scale ตาม workload
ตัวอย่างเช่น หากองค์กรต้องการรัน model ขนาดใหญ่หรือให้บริการ inference กับผู้ใช้จำนวนมาก จำเป็นต้องออกแบบ compute, memory, GPU allocation และ load balancing ให้เหมาะสมตั้งแต่ต้น
2. Model Deployment and Serving
การ deploy โมเดลไม่ใช่แค่การเปิด service ให้รันได้ แต่ต้องออกแบบให้รองรับการใช้งานจริง เช่น การเปิด API, การจัดการ concurrency, การทำ autoscaling, การแบ่งทรัพยากร และการจัดการหลาย model ในระบบเดียว
เครื่องมือที่มักเกี่ยวข้องในส่วนนี้ เช่น vLLM, KServe, Ray Serve และ serving platform บน Kubernetes
3. RAG and Data Integration
หลายองค์กรไม่ได้ต้องการเพียงโมเดลที่ตอบเก่งทั่วไป แต่ต้องการโมเดลที่อ้างอิงข้อมูลจริงขององค์กร เช่น เอกสารภายใน คู่มือบริษัท นโยบาย หรือฐานความรู้เฉพาะทาง
LLMOps จึงครอบคลุมการวางระบบ RAG (Retrieval-Augmented Generation) เพื่อเชื่อม LLM เข้ากับข้อมูลภายใน ช่วยให้คำตอบแม่นยำขึ้นและมีบริบทที่ตรงกับธุรกิจมากขึ้น
4. Monitoring and Observability
ระบบ LLM ที่ดีต้องวัดผลได้ ไม่ว่าจะเป็น latency, throughput, token usage, error rate, GPU utilization หรือคุณภาพของคำตอบ เพราะหากไม่มีการมองเห็นระบบอย่างชัดเจน การ optimize และแก้ปัญหาจะทำได้ยากมาก
5. Security and Governance
สำหรับองค์กร เรื่อง security เป็นหัวใจสำคัญ โดยเฉพาะเมื่อ LLM เชื่อมต่อกับข้อมูลภายใน การออกแบบระบบต้องคำนึงถึง access control, audit log, data isolation, secret management และนโยบายการใช้งานข้อมูลอย่างเหมาะสม
6. Cost Optimization
งาน LLM มักมีต้นทุนสูง โดยเฉพาะเมื่อเกี่ยวข้องกับ GPU หรือ external model APIs ดังนั้น LLMOps ที่ดีต้องช่วยให้สามารถ optimize cost ได้ เช่น การเลือก serving architecture ที่เหมาะสม การจัดสรร GPU อย่างมีประสิทธิภาพ การ caching และการวาง workload ให้เหมาะกับขนาดโมเดล
ตัวอย่างการใช้งาน LLMOps ในองค์กร
AI Chatbot สำหรับพนักงาน
องค์กรสามารถใช้ LLM เพื่อสร้างระบบตอบคำถามจากเอกสารภายใน เช่น HR policy, IT knowledge base หรือ operation manual ทำให้พนักงานเข้าถึงข้อมูลได้เร็วขึ้น
Private LLM สำหรับข้อมูลสำคัญ
บางองค์กรต้องการ deploy โมเดลใน private environment เพื่อควบคุมข้อมูลและความปลอดภัย เช่น ธุรกิจด้านการเงิน สุขภาพ หรืออุตสาหกรรมที่มีข้อมูลอ่อนไหว
RAG สำหรับค้นหาความรู้จากเอกสารจำนวนมาก
เมื่อต้องจัดการเอกสารจำนวนมาก เช่น สัญญา คู่มือ รายงาน หรือ technical documents ระบบ RAG ที่ดีจะช่วยให้การค้นหาและสรุปข้อมูลมีประสิทธิภาพมากขึ้น
Model Serving สำหรับ AI Applications
LLMOps ยังเหมาะกับองค์กรที่ต้องการใช้โมเดลเป็น backend ของระบบต่าง ๆ เช่น AI assistant, customer support bot, internal search หรือ workflow automation
องค์กรแบบไหนที่ควรเริ่มทำ LLMOps
LLMOps เหมาะกับองค์กรที่มีเป้าหมายใช้งาน AI อย่างจริงจัง โดยเฉพาะกรณีเหล่านี้:
- มีการทดสอบ LLM แล้วและต้องการยกระดับขึ้นสู่ Production
- ต้องการเชื่อม AI เข้ากับข้อมูลภายในองค์กร
- ต้องการควบคุมข้อมูล ความปลอดภัย และต้นทุนด้วยตัวเอง
- ต้องการ deploy โมเดลบน cloud, on-premise หรือ hybrid environment
- มี use case ที่เกี่ยวข้องกับ chatbot, copilots, knowledge search หรือ document intelligence
LLMOps ต่างจาก MLOps อย่างไร
MLOps มักเน้นการบริหารจัดการวงจรชีวิตของ machine learning models โดยรวม เช่น data pipeline, experiment tracking, training pipeline, model registry และ deployment สำหรับ supervised learning หรือ predictive models
ส่วน LLMOps จะโฟกัสเฉพาะความท้าทายของ Large Language Models ซึ่งมีรายละเอียดเฉพาะตัวมากกว่า เช่น prompt flow, token usage, context handling, model serving performance, RAG pipeline, vector database integration และ governance ของ generative AI
สรุปคือ LLMOps ถือเป็นชุดแนวปฏิบัติที่เฉพาะทางมากขึ้นสำหรับองค์กรที่ใช้ generative AI และ LLM เป็นแกนหลัก
หากองค์กรต้องการเริ่มต้น LLMOps ควรเริ่มจากอะไร
แนวทางที่ดีในการเริ่มต้นคือ:
- ประเมิน use case ที่ต้องการใช้งานจริงก่อน
- เลือก architecture ที่เหมาะกับขนาดงานและข้อกำหนดด้านข้อมูล
- วางแผนเรื่อง model serving, data integration และ RAG ตั้งแต่ต้น
- เตรียม monitoring, security และ cost control ให้พร้อมก่อนขึ้น production
- ออกแบบ platform ให้รองรับการขยายในอนาคต
การเริ่มต้นที่ดีจะช่วยให้องค์กรไม่ต้องย้อนกลับมาแก้ระบบในภายหลัง ซึ่งมักมีต้นทุนสูงกว่า
สรุป
LLMOps คือรากฐานสำคัญของการใช้งาน Large Language Models ในระดับองค์กร เพราะช่วยให้การ deploy, เชื่อมต่อข้อมูล, ดูแลระบบ, ควบคุมต้นทุน และรักษาความปลอดภัย ทำได้อย่างเป็นระบบและพร้อมใช้งานจริง
Comments are closed